[Vulkan]Wave Programming (Subgroup)
keywords: Graphics, Vulkan Subgroup, D3D12 Warp, Wave Intrinsics, Wavefronts, SIMD, GPU Scalarization
Overview
- Vulkan/OpenCL calls it a Subgroup
- D3D12 calls it a Wave
- Nvidia calls it a Warp
- AMD calls it a Wavefront
Quoted from GPU Occupancy (PIX GPU Captures):
On NVIDIA GPUs, in addition to timing data, PIX can gather information about shader execution within a single event.
GPUs are usually constructed as a hierarchy of repeated blocks, where each level might share a resource. For example, an imaginary GPU might be structured like this:
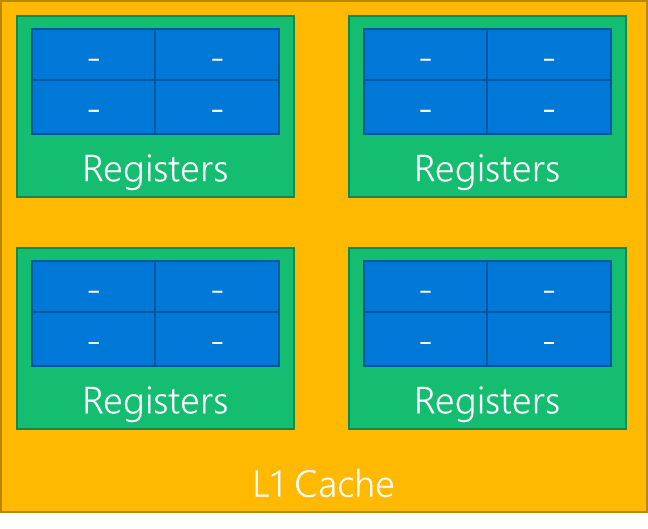
As all the blues share a single set of registers, if a workload needs all the registers then only one wave at a time can execute in the green block. In this case the occupancy of the green block would be 1, out of a total possible occupancy of 4.
At any point in time, all the green blocks may be executing different number of waves. Of the four green blocks above, one might be executing 3 waves, another 2 waves, and the remaining 1 wave. PIX boils all this data down to a single value – the maximum occupancy, which would be 3 in this example.
This is presented in PIX in the Occupancy lane, which shows the maximum occupancy, separated by shader stage. This is an indication of how much work the GPU is able to do in parallel – higher bars show better GPU utilization.
Documents
Wave Programming in D3D12 and Vulkan - GDC2017
https://gpuopen.com/wp-content/uploads/2017/07/GDC2017-Wave-Programming-D3D12-Vulkan.pdf
Surfing the Wave(front)s with Radeon GPU Profiler
https://gpuopen.com/presentations/2019/Surfing_the_Wavefronts.pdf
Occupancy explained
https://gpuopen.com/learn/occupancy-explained/
SIMD in the GPU world
https://www.rastergrid.com/blog/gpu-tech/2022/02/simd-in-the-gpu-world/
Subgroups - 2018 Vulkan Devday
https://www.khronos.org/assets/uploads/developers/library/2018-vulkan-devday/06-subgroups.pdf
Wave Intrinsics
https://github.com/Microsoft/DirectXShaderCompiler/wiki/Wave-Intrinsics
Unlocking GPU Intrinsics in HLSL
https://developer.nvidia.com/blog/unlocking-gpu-intrinsics-in-hlsl/
Wave Intrinsics - Intel® Arc™ A-series Graphics Gaming API
HLSL 6.0 wave operations
https://learn.microsoft.com/en-us/windows/win32/api/d3d12/ns-d3d12-d3d12_feature_data_d3d12_options1
INTRO TO GPU SCALARIZATION – PART 1 (Recommended)
https://flashypixels.wordpress.com/2018/11/10/intro-to-gpu-scalarization-part-1/
INTRO TO GPU SCALARIZATION – PART 2 -SCALARIZE ALL THE LIGHTS
https://flashypixels.wordpress.com/2018/11/10/intro-to-gpu-scalarization-part-2-scalarize-all-the-lights/
Blogs
Visualizing GL_NV_shader_sm_builtins
https://wunkolo.github.io/post/2020/02/visualizing-gl_nv_shader_sm_builtins/
Forums
Quote from gamedev.net:
None of the things you’ve quoted are contractory – the first quote says that a wavefront is 64 threads, not that a wavefront is 1 thread.
A SIMD unit can have up to 10 wavefronts in flight at once. Each wavefront contains 64 threads. Hence a SIMD unit can have up to 640 threads in flight at once (in multiples of 64).
The scheduler will take the pixels/vertices that need to be processed, allocate one thread per pixel/vertex, and then tries to group up to 64 threads together into a wavefront. That bundle of threads is then given to a SIMD, which runs the shader code.
The number of wavefronts that ‘fit’ into a SIMD depends on the complexity of the shader code. For simple shaders, you can squeeze 10 wavefronts at a time into a SIMD, but for complex shaders you may only be able to fit one or two wavefronts into a SIMD.
This is because different shaders require different numbers of temporary registers, which are stored in the SIMD’s register array. Say the SIMD has 1000 registers in total – if a shader uses 100 or less, then you can fit 10 (or more) “instances” of that shader into the register array. If a shader uses 500 temporary registers, then only two “instances” of that shader will fit into the SIMD - so the SIMD will only accept two concurrent wavefronts.
Each “register” actually contains 64 floats – which is why this calculation is done for wavefronts and not threads. One register is used by a wavefront to store a value for each of it’s threads.
What’s a “wavefront” in the context of real-time rendering?
https://stackoverflow.com/a/70249817/1645289
Clustered shading - why deferred?
https://www.gamedev.net/forums/topic/683544-clustered-shading-why-deferred/
What are screen space derivatives and when would I use them?
https://gamedev.stackexchange.com/a/130933/117871
Teachers open the door, but you must enter by yourself. -Chinese Proverbs